
표본표준편차에 관한 질문
게시글 주소: https://orbi.kr/0002814830
미적분과 통계기본 개념서들에 보면
'모평균의 추정과 신뢰도' 파트에서
모집단의 분포가 정규분포를 따를때 모평균 m은 다음 범위에 있다.(X는 표본평균, n은 표본의 크기 , 델타는 표준편차)
95%의 신뢰도로서 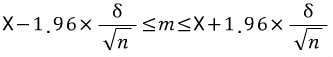
*그리고 실제로 모집단의 표준편차 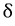 를 모르는 경우가 대부분이다. 이때 표본표준편차를 이용해도 위의 신뢰도는 성립한다.
를 모르는 경우가 대부분이다. 이때 표본표준편차를 이용해도 위의 신뢰도는 성립한다.
그런데 제가 궁금한건 모집단의 표준편차 를 모른다고 표본표준편차를 위의 식에 넣어도 성립한다는 건데
표본표준편차란 대체 무엇이죠??? 표본평균의 표준편차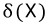 와는 다른건가요??? =
와는 다른건가요??? = 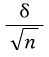 라고 알고 잇는데 이걸 대입하라는 소리는 당연히 아니겠죠?;;;;
라고 알고 잇는데 이걸 대입하라는 소리는 당연히 아니겠죠?;;;;
설명좀부탁드립니다. ㅠㅠㅠㅠㅠ
0 XDK (+0)
유익한 글을 읽었다면 작성자에게 XDK를 선물하세요.
-

공부좀 잘하고싶다 0 0
난 왤케 멍청할까 뭐 하위권 비하 이런게 아니라 주변이 서카포연고의치한이딴 애들밖에...
-


뱃지까지 따라해보셈 1 0
ㅋ
-

다들 모함? 6 0
빨간날인데
-

폭사한 칠수생 있었는데 참 무섭더라 영문만 빼고 다 붙는 점수였음 근데 컨설팅 받고...
-

아날로그열품타 1 0
-

쪽지 주면 비번 알랴줌 없으면 말구...
-

오르비 >> 나한텐 약간 4 3
대화가 허용된 재수학원 느낌임 뭔가 여기서 올해 입시에 임하는 모두가 다같이...
-

ㅈ댓다ㅈ댓닺댓다자댓다 0 0
11시에 일어나버림
-


작수성적이고 6모 보니까 91 100 78 40 50 (원점수) 일케 나왔는데...
-


성수 가서 규카츠를 먹고 2 0
분위기 좋은 카페로 가서 수플레를 먹어야겠다
-

친구랑 열품타 비교하면 현타옴 9 0
(첫번째가 저고 두번째가 친구) 나도 열심히 한답시고 하는데..
-

국어 기출 90점 나와서 기뻤는데 바로 우울해짐 5 0
2컷이 92점이라
-
3모 5에가까운4 5모 (63점)5점차로 5 6모 (73점)5에가까운 4 7모...
-

하지만 25같은 해에도 3패하신 분이 계시긴 함
-

이분 ㄹㅇ 레전드임 4 2
어제 리트 해설 찾아보다가 비교적 최근에 글쓰신거 봤는데 전국예상석차 6등 ㄷㄷㄷ...
-

역시 최신 유행은 강평 ㅋㅋ
-

예를 들어 대학은 별로 안 중요하다 라는 발언을 한다면 1. 서울대, 의대생이 함...
-
더프 등급컷 예상 0 0
7덮 보정컷 예상 (1컷) 국어 수학 언매 90 미적 84
-

반수 스카 독재 하는중 1 1
장점: 돈이 별로 안 듬 내가 필요한 공부만 할 수 있음 피곤하면 커피 사마시러...
-

점매추 2 0
뭐먹지
-


아오 2 1
-
덮 국어 현대시 안어려웠나요? 2 0
20번 푸는데 답이 너무 여러개같아서 시간을 넘 많이 써버렸는데 다시 풀어보는데도...
-

다 넣어서 먹으니 마이 맵네
-
지금은 아스카지만 1 0
옛날엔 토가가 좋았어
-


안녕하세요 정시의벽입니다 10 8
군복무 중 저의 미래에 대해 생각해본 결과 수능을 응시하여 서울대학교 의예과에...
-

덕코기부 6 0
받습니다
-
7덮 수학 30번 0 0
7덮 30번 현장에서 틀리긴 했는데 다시 풀어보았습니다적분 치환하는 과정에서...
-

영단어장 추천좀 해주세요 2 0
1~2등급 정도 되는데 조금 어려운 단어장 잇을까요
-

안녕하세요. 오르비 전자책 1위 저자 발로탱이입니다. 몇 년째 베스트셀러인 지구과학...
-
미적분1 확통 문제집 풀려는데 RPM이 좋을까요 쎈이 좋을까요? 내신대비+수능대비...
-

도서관+스카독재하는데 4 1
가장 힘든 점: 아침에 일어나기 막상 일어나면 가서 하는건 괜찮음
-

설대 곰임형 갖고 싶다 1 1
-

점심추천 0 1
너무 매운 건 제외요
-
도시락 이즈 낫 굿
-
오답노트가 도움이 됨? 0 0
고1때는 그래도 올1등급에 나름 전과목 심화반 다 드간 우?등생? 이었는데 그때...
-

나스닥 선물 지옥이네 3 0
이 정도면 AI가 버블일 경우에나 가능한 주가 수준인데
-
7덮 수학 85 0 0
1 가능할까요 ㅜㅜ
-

고1 3모부터 한번도 빠짐없이 늘 순서대로 풀었는데… 이번 7모에서 독서문학 다...
-


약물의 힘을 빌려야하나? 1 0
아침에 실모풀면 착착 안감기고 자꾸 처지네 뇌 풀가동을 위한.. 무언가가 필요한데
-

니들은 꼭 잇올이나 재종 다녀라 14 3
무휴반 스카 반수 예정인데 진짜 맨날 늦잠자고 공부 안 하고 빈둥빈둥 돌겟다
-

올해 투과목 만표 전부 0 0
62
-
얼리?버드 12 0
그야 4시에 잤거덩
-
나는 오답같은거 안해 2 0
무서워서
-

근데 내가 24수능을 봤는데 0 0
왜 잊음을 논함은 시간없어서 풀지를 못했음
-

지금 쓰는건 땀나면 질척거려서
-

슬프다 4 1
-

정시란건뭐든할수있는전형이니까 5 5
하고싶은게뭐든꿈꿀수있어 -고2담임t- ....
-

내일이면 시험이내 11 0
오늘 집중 1도 안되내
-
이제 일어남 2 0
어제 치대선배하고 3시간 디코해서 치대가기위해 스카간다
-
정벽 개새끼야 6 5
ㅂㅅ

뭘 궁금해하시는지 대략 알 것 같아서 내용은 제대로 안 읽었습니다만, 해결이 될 겁니다.
'표본표준편차'와 '표본평균의 표준편차'는 당연히 서로 다릅니다.
예를 들어서, 한국에 있는 고3 학생들의 키를 생각합시다. 몇 십만 명 될까요? (모)평균은 170이라 치구요.
'표본평균'은, 여기서 100명의 학생을 임의로 뽑았는데, 그 학생들의 평균키입니다. 중요한 건, 그냥 '표본평균'은 '변수'입니다. 정해진 수가 아니란 말이죠. 즉, 서울에서 100명을 한 번 뽑아 평균 내는거랑, 부산에서 100명을 한 번 뽑아 평균 내면 차이가 있겠죠? 170에 근접할 거라는 건 예상할 수 있습니다. 우연히 좀 큰 놈들만 뽑으면 175가 나올 수도 있겠지요.
'표본평균의 평균'은, 방금 말한 변수 표본평균들의 평균입니다. 즉, 서울에서 100명 뽑고 부산 100명 대구 100명 여러 동네에서 100명 씩 뽑으면 변수가 여러 개 있죠? 그것들의 평균입니다. 서울 애들의 평균 169 부산은 평균 170 대구는 171, 대충 170 근처에서 형성되겠죠? 그래서 표본평균의 평균은 모평균과 같습니다.(정확히 왜 같은 지는 책에 증명이 있는지는 모르겠는데, 직관적으로 받아들일 수 있겠죠?)
'표본평균의 표준편차'는, 말 그대로인데, 표본평균은 100명의 평균이니까, 모평균에 근접할 겁니다. 전국의 어느 지역에서든 100명을 뽑아 키를 평균내면(표본평균) 진짜 특이한 동네를 제외하고는 그 평균이 170에 근접하지 않겠어요? 그러므로 170에서 흩어진 정도가 작으니까 표준편차는 작을 수 밖에요. 그걸 루트n으로 나눠줬다고 생각하시면 됩니다.
모평균을 추정할 땐 100명 씩 여러 번 뽑을 필요 없이, 서울 애들 100명 한 번만 뽑아서 모평균을 추정합니다. 여러 번 뽑으면 귀찮잖아요. 통계조사하는 이유도 없구요. 서울의 학생들이 가장 표준적이라 생각해서, 서울 애들 100명 뽑아 키를 측정합니다. 이 애들의 평균은 위에서 말한 '표본평균'인데, 이 100명 간에도 표준편차가 있을 겁니다. 이것이 '표본표준편차'이구요. 이건 전국 모든 학생들의 표준편차(모표준편차)와 같습니다. 전국 학생들의 키의 분포가 155~165에 30%, 165~175에 40%, 175~,185에 30%라고 칩시다. 임의로 뽑은 서울 애들의 키는 위의 분포와 비슷하겠죠? 물론 100% 같다고 할 순 없지만, 거기에 근접할 거라는 건 생각할 수 있죠. 그래서 모표준편차 자리에 집어넣어도 되는 겁니다.
말재주가 없어서 간단한 내용을 너무 어렵게 말한 게 아닌가 걱정되네요. 궁금하시면 다시 물어보세요~
아니에요 ㅎㅎ 예시까지 제시해주셔서 헷갈리던 부분이 이해가 깔끔하게 되었습니다.
친절하고 긴 답변 감사드립니다^^